library(reticulate)
#fill in "name"
use_python(“C:/Users/name/anaconda3/envs/r-tensorflow/python.exe”, required=TRUE)
py_config()
#test
library(tensorflow)
tf$constant(“TensorfFlow is Working!”)Seminar 3
Overview
The goal of seminar 3 is to review the questions in Problem Set 2. Many of these questions do no require R and a selection will be discussed in person during class. Here, you will find an initial attempt at Q4.
Question 4: Please try working through the coding example in the week 6’s lecture note on the feedforward neural network.
Exercise 1 Try to run the following code on your own computer. You should be able to replicate the results in the slides for a 128-128-128 architecture. Next, modify the code to replicate other architectures.
Load packages and data
Updating R and installing
tensorflow
I had issues with some of the packages and needed to update to the latest version of R (4.2.2.).
You will need to install a python package called tensorflow. There are two ways to do this that may need some troubleshooting depending on your set-up.
Option 1. Install tensorflow in python separately. You can do this easily, using pip install tensorflow in the Anaconda Prompt terminal. You will likely be encouraged to install tensorflow in a virtual environment. If you do this, you will then need to change the Python environment in R.
You can do this in two ways:
- In RStudio, go to Tools>Global Options…>Python. Use the “Select” button to change the environment for the current session.
- Use the
reticulatepackage to change the environment.
Option 2. Install tensorflow from within RStudio.
install.packages("tensorflow")
tensorflow::install_tensorflow()
library(tensorflow)
tf$constant("TensorFlow is working!")
library(reticulate)
py_config()I had trouble installing and running tensorflow. Due to some decisions I made along the way, I now require the additional code:
library(reticulate)
reticulate::use_python("C:/Users/neil_/anaconda3/python.exe")I hope you don’t have the same trouble!
After successfully installing tensorflow load the libraries.
library(tensorflow)
library(keras)
library(ggplot2)We will use a data that comes with R: “Boston”. It 506 observations and 14 variables. The outcome we aim to predict is “medv”: the median value of owner occupied homes (in ’000s dollars). The number of predictors is \(p=13\).
# Load the Boston dataset
library(MASS)
data <- Boston Create training and testing database
As in Seminar 2, we need to split the data into a training and testing sample. Take note of the normalization step. We missed this step in Seminar 2.
set.seed(6)
x <- as.matrix(data[, -ncol(data)]) # All columns except the last (predictors)
y <- as.numeric(data[, ncol(data)]) # The last column
x <- scale(x) # Normalize the predictors
# Split the data
test_proportion <- 0.2 # Define the proportion of the test set
n <- nrow(data)
test_indices <- sample(1:n, size = floor(test_proportion * n))
train_indices <- setdiff(1:n, test_indices) # find all indices that are not in test_indices
x_train <- as.matrix(x[train_indices, ])
y_train <- as.numeric(y[train_indices])
x_test <- as.matrix(x[test_indices, ])
y_test <- as.numeric(y[test_indices])Execute Feedforward Neural Network
To begin, we will execute a model with a 128-128-128 architecture:
- width \(q=128\);
- depth \(r=3\);
- activation function \(g = ReLU\)
This means that the number of parameters (weights) will be,
\[ \underbrace{(13+1)\cdot128}_\text{Layer 1} + \underbrace{(128+1)\cdot128}_\text{Layer 2} + \underbrace{(128+1)\cdot128}_\text{Layer 3}+\underbrace{128+1}_\text{Output Layer} = 34,945 \]
# Input layer
input <- layer_input(shape = c(ncol(x_train)))
output <- input %>%
layer_dense(units = 128, activation = "relu") %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = 128, activation = "relu") %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = 128, activation = "relu") %>%
layer_dropout(rate = 0.5) %>%
layer_dense(units = 1) # Single output layer
model <- keras_model(inputs = input, outputs = output)
# Configure the model
tensorflow::tf$keras$Model$compile(
model,
loss = "mse", # Mean Squared Error
optimizer = tensorflow::tf$keras$optimizers$Adam(),
metrics = list("mae") # Mean Absolute Error
) # Train the model
history <- tensorflow::tf$keras$Model$fit(
model,
x = tensorflow::tf$convert_to_tensor(x_train), # Convert x to TensorFlow Tensor
y = tensorflow::tf$convert_to_tensor(y_train), # Convert y to TensorFlow Tensor
epochs = 50L, # Number of epochs, L indicates integer;
batch_size = 32L, # Batch size
validation_split = 0.2 # Use 20% of the data for validation
)Epoch 1/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m22s[0m 2s/step - loss: 689.5551 - mae: 24.4692
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m3s[0m 33ms/step - loss: 628.0851 - mae: 23.2673 - val_loss: 231.1659 - val_mae: 14.2423
Epoch 2/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 490.0184 - mae: 20.1199
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 495.0543 - mae: 20.3299 - val_loss: 141.2276 - val_mae: 10.3903
Epoch 3/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 331.0157 - mae: 16.0697
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 12ms/step - loss: 264.7611 - mae: 13.9956 - val_loss: 60.5894 - val_mae: 6.4758
Epoch 4/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 101.1181 - mae: 7.9549
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 99.1883 - mae: 7.8011 - val_loss: 47.5501 - val_mae: 5.7522
Epoch 5/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 71.2275 - mae: 5.9820
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 96.5553 - mae: 7.0774 - val_loss: 45.2462 - val_mae: 5.4967
Epoch 6/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 39.8872 - mae: 5.3088
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 66.2081 - mae: 6.3266 - val_loss: 41.6517 - val_mae: 5.2288
Epoch 7/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 27ms/step - loss: 50.0161 - mae: 5.0964
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 62.2262 - mae: 5.8205 - val_loss: 38.1698 - val_mae: 4.9880
Epoch 8/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 44.1734 - mae: 5.2707
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 58.2122 - mae: 5.7769 - val_loss: 37.1171 - val_mae: 4.9102
Epoch 9/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 38ms/step - loss: 56.5878 - mae: 5.4311
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 56.0823 - mae: 5.7323 - val_loss: 34.1220 - val_mae: 4.7215
Epoch 10/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 64.6227 - mae: 6.7946
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 55.5275 - mae: 5.8702 - val_loss: 33.4966 - val_mae: 4.6757
Epoch 11/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 32.8004 - mae: 4.5381
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 58.2897 - mae: 5.6734 - val_loss: 33.2381 - val_mae: 4.6394
Epoch 12/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 35.0458 - mae: 4.6946
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 53.3897 - mae: 5.4994 - val_loss: 30.9257 - val_mae: 4.4722
Epoch 13/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 82.0047 - mae: 6.7336
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 60.4770 - mae: 5.9668 - val_loss: 27.5460 - val_mae: 4.1768
Epoch 14/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 32ms/step - loss: 48.4893 - mae: 5.7550
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 48.9833 - mae: 5.4841 - val_loss: 29.2070 - val_mae: 4.3032
Epoch 15/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 32ms/step - loss: 34.4505 - mae: 4.9218
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 51.1002 - mae: 5.5813 - val_loss: 25.9550 - val_mae: 4.0207
Epoch 16/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 38.9243 - mae: 5.0070
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 47.4817 - mae: 5.2076 - val_loss: 25.9668 - val_mae: 3.9739
Epoch 17/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 86.5412 - mae: 6.5236
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 54.2851 - mae: 5.4987 - val_loss: 22.9260 - val_mae: 3.6931
Epoch 18/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 41.1477 - mae: 5.2850
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 51.9624 - mae: 5.5908 - val_loss: 23.0947 - val_mae: 3.6264
Epoch 19/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 45.1620 - mae: 5.2506
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 43.3628 - mae: 4.9506 - val_loss: 23.7447 - val_mae: 3.6919
Epoch 20/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 21.4861 - mae: 3.9764
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 41.6584 - mae: 4.8637 - val_loss: 21.1909 - val_mae: 3.4261
Epoch 21/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 29.3402 - mae: 4.2791
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.7252 - mae: 4.8300 - val_loss: 21.8536 - val_mae: 3.4931
Epoch 22/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 49.0534 - mae: 5.3895
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 44.9081 - mae: 5.1512 - val_loss: 20.2437 - val_mae: 3.3453
Epoch 23/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 29.3735 - mae: 4.3542
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 35.9293 - mae: 4.6903 - val_loss: 19.1758 - val_mae: 3.3033
Epoch 24/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 32ms/step - loss: 42.6983 - mae: 4.8196
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 54.8558 - mae: 5.5861 - val_loss: 21.2709 - val_mae: 3.4362
Epoch 25/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 30.1738 - mae: 4.5161
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.3444 - mae: 4.9715 - val_loss: 21.4934 - val_mae: 3.4464
Epoch 26/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 35.3122 - mae: 4.7983
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 39.7620 - mae: 4.9163 - val_loss: 21.0186 - val_mae: 3.3847
Epoch 27/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 27ms/step - loss: 26.5361 - mae: 4.1525
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 47.9204 - mae: 5.0488 - val_loss: 20.2418 - val_mae: 3.3162
Epoch 28/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 99.7565 - mae: 8.1418
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 57.6950 - mae: 5.9128 - val_loss: 22.8760 - val_mae: 3.6585
Epoch 29/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 39.5229 - mae: 4.9653
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 42.3745 - mae: 4.9169 - val_loss: 23.6032 - val_mae: 3.7503
Epoch 30/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 49.5030 - mae: 5.3322
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 45.3675 - mae: 5.1060 - val_loss: 23.3391 - val_mae: 3.7161
Epoch 31/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 34.5553 - mae: 4.4793
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 43.1995 - mae: 4.9744 - val_loss: 18.4998 - val_mae: 3.1744
Epoch 32/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 33ms/step - loss: 28.7278 - mae: 4.5667
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 36.7190 - mae: 4.7354 - val_loss: 18.2170 - val_mae: 3.1817
Epoch 33/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 28.6269 - mae: 4.2149
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 44.9428 - mae: 5.0375 - val_loss: 20.0228 - val_mae: 3.3484
Epoch 34/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 37ms/step - loss: 57.2449 - mae: 6.0325
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 44.3474 - mae: 5.2479 - val_loss: 18.8312 - val_mae: 3.2175
Epoch 35/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 44.3587 - mae: 5.3770
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.7099 - mae: 4.9043 - val_loss: 18.9102 - val_mae: 3.2459
Epoch 36/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 45.6255 - mae: 5.3796
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 39.0158 - mae: 4.7060 - val_loss: 18.6573 - val_mae: 3.2269
Epoch 37/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 38.3910 - mae: 4.7404
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.0344 - mae: 4.8988 - val_loss: 17.5208 - val_mae: 3.0985
Epoch 38/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 25.7330 - mae: 4.1183
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 41.3704 - mae: 4.9453 - val_loss: 16.7105 - val_mae: 3.0033
Epoch 39/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 36.5605 - mae: 4.4369
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 40.0485 - mae: 4.7192 - val_loss: 17.0620 - val_mae: 3.0374
Epoch 40/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 50.0592 - mae: 5.2442
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 43.4579 - mae: 5.0555 - val_loss: 18.0735 - val_mae: 3.1809
Epoch 41/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 35.1892 - mae: 4.6067
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 33.4224 - mae: 4.4041 - val_loss: 17.8846 - val_mae: 3.1640
Epoch 42/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 34ms/step - loss: 50.6706 - mae: 5.3024
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 41.5095 - mae: 4.7731 - val_loss: 16.2472 - val_mae: 2.9724
Epoch 43/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 53.5104 - mae: 5.5309
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.0559 - mae: 4.8937 - val_loss: 16.7101 - val_mae: 3.0012
Epoch 44/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 36.4219 - mae: 4.6888
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 42.1914 - mae: 4.8741 - val_loss: 16.8998 - val_mae: 3.0745
Epoch 45/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 31ms/step - loss: 33.3051 - mae: 4.8560
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 42.2671 - mae: 4.9946 - val_loss: 16.3686 - val_mae: 2.9832
Epoch 46/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 54.5692 - mae: 5.0043
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 38.9898 - mae: 4.5786 - val_loss: 15.9083 - val_mae: 2.9621
Epoch 47/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 32.0412 - mae: 4.4798
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 37.9167 - mae: 4.6615 - val_loss: 17.2492 - val_mae: 3.1539
Epoch 48/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 28ms/step - loss: 46.9966 - mae: 5.2159
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 48.7749 - mae: 4.9650 - val_loss: 15.7270 - val_mae: 2.9691
Epoch 49/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 29ms/step - loss: 48.7861 - mae: 4.3676
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 10ms/step - loss: 36.9421 - mae: 4.3206 - val_loss: 15.6015 - val_mae: 2.9523
Epoch 50/50
[1m 1/11[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m0s[0m 30ms/step - loss: 49.5210 - mae: 4.9202
[1m11/11[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 9ms/step - loss: 39.6472 - mae: 4.7467 - val_loss: 16.3102 - val_mae: 3.0015# Predictions
predictions <- tensorflow::tf$keras$Model$predict(model, tensorflow::tf$convert_to_tensor(x_test))
[1m1/4[0m [32m━━━━━[0m[37m━━━━━━━━━━━━━━━[0m [1m0s[0m 67ms/step
[1m4/4[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 22ms/step# Print the result
tensorflow::tf$keras$Model$summary(model)Model: "functional"
┌─────────────────────────────────┬────────────────────────┬───────────────┐
│ Layer (type) │ Output Shape │ Param # │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ input_layer (InputLayer) │ (None, 13) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_3 (Dense) │ (None, 128) │ 1,792 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_2 (Dropout) │ (None, 128) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 128) │ 16,512 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_1 (Dropout) │ (None, 128) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 128) │ 16,512 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 128) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 1) │ 129 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 104,837 (409.52 KB)
Trainable params: 34,945 (136.50 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 69,892 (273.02 KB)Extract the final training and validation loss
final_training_loss <- history$history$loss[length(history$history$loss)]
final_validation_loss <- history$history$val_loss[length(history$history$val_loss)]
cat("Final Training Loss:", final_training_loss, "\n")Final Training Loss: 38.97892 cat("Final Validation Loss:", final_validation_loss, "\n")Final Validation Loss: 16.31018 Visualize the results
Convert history to a data frame with epoch numbers
history_df <- as.data.frame(history$history)
history_df$epoch <- seq_len(nrow(history_df))Plot training and validation loss
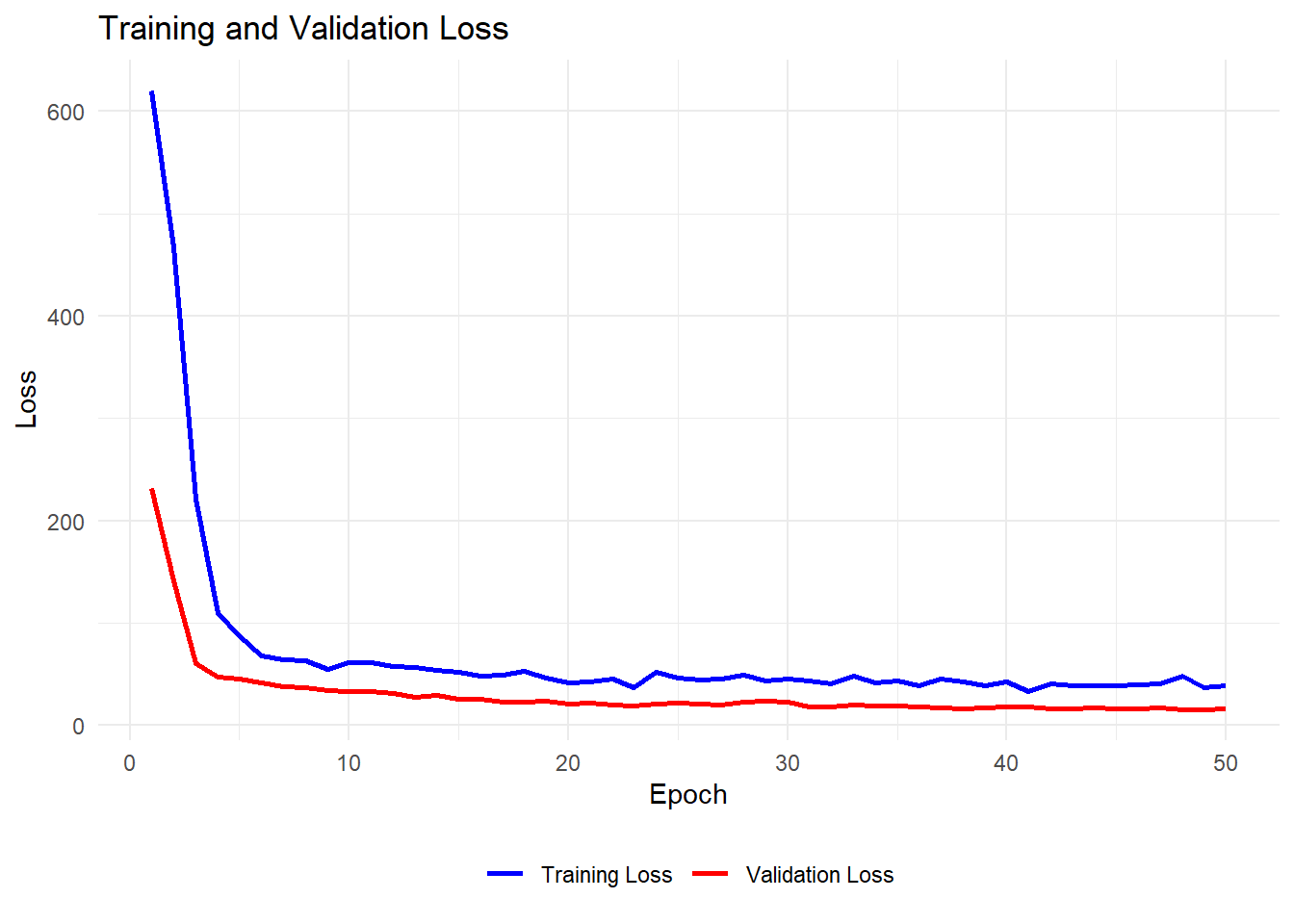
ggplot(history_df, aes(x = epoch)) +
geom_line(aes(y = loss, color = "Training Loss"), linewidth = 1) +
geom_line(aes(y = val_loss, color = "Validation Loss"), linewidth = 1) +
labs(
title = "Training and Validation Loss",
x = "Epoch",
y = "Loss"
) +
scale_color_manual(values = c("blue", "red")) +
theme_minimal() +
theme(
legend.title = element_blank(),
legend.position = "bottom" # Options: "top", "bottom", "left", "right", or c(x, y) for custom
)
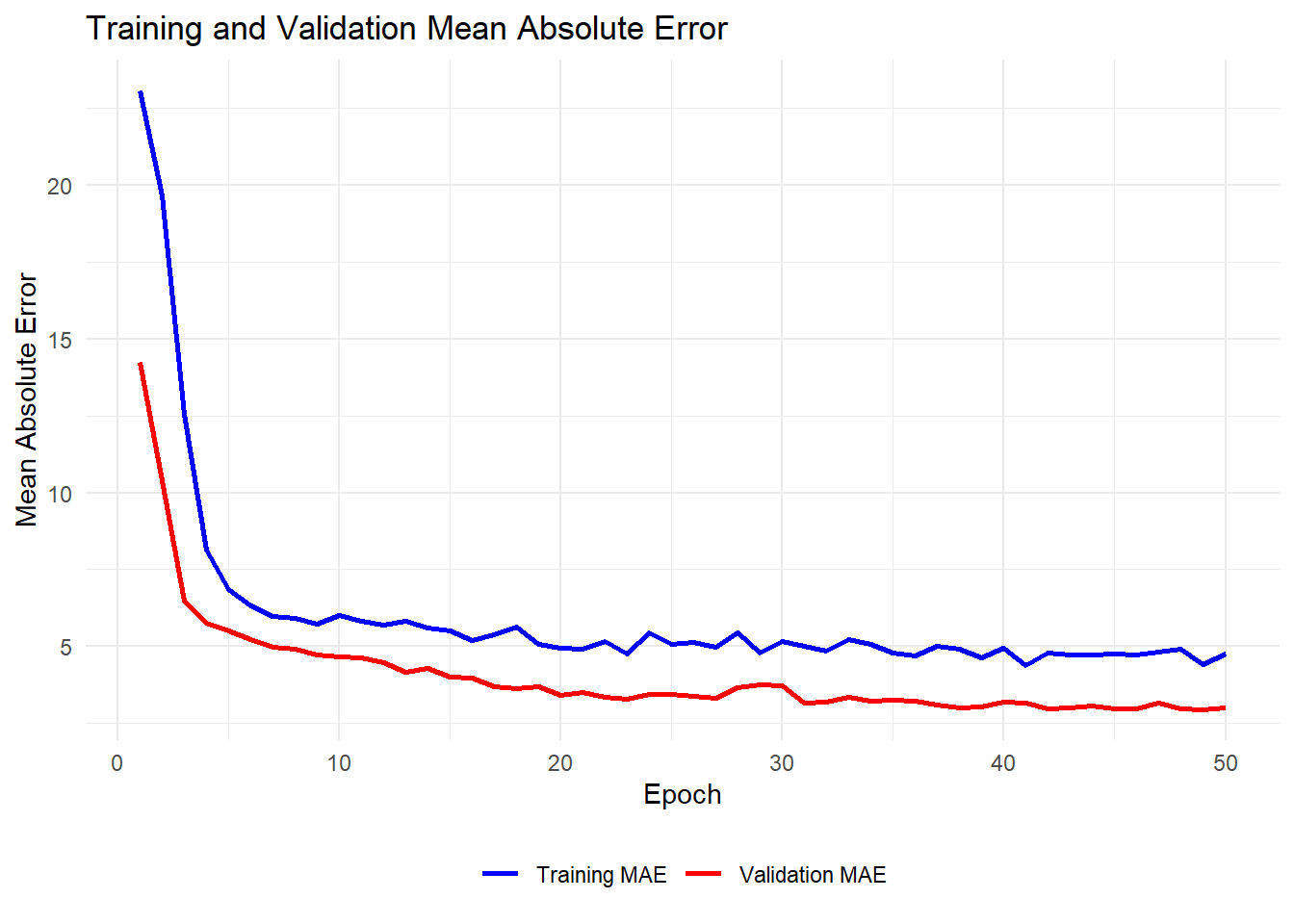
Plot training and validation mean absolute error (MAE)
ggplot(history_df, aes(x = epoch)) +
geom_line(aes(y = mae, color = "Training MAE"), linewidth = 1) +
geom_line(aes(y = val_mae, color = "Validation MAE"), linewidth = 1) +
labs(
title = "Training and Validation Mean Absolute Error",
x = "Epoch",
y = "Mean Absolute Error"
) +
scale_color_manual(values = c("blue", "red")) +
theme_minimal() +
theme(
legend.title = element_blank(),
legend.position = "bottom" # Options: "top", "bottom", "left", "right", or c(x, y) for custom
)